「階層型」のデータ構造は業務システムでしばしば目にするものだが、苦手意識を持っている開発者が少なくない。その原因として「自己参照型」と「部品表型」とが区別できていない点を指摘できる。これらを確実に区別して、ややこしい階層構造を攻略しよう。
■自己参照型と部品表型
まずは、比較的わかりやすい「自己参照型」について説明しよう。インスタンス付きのデータモデルを見てもらえばよくわかる(図1)。組織レコードが「上位組織ID」で他の組織レコードを参照するので「自己参照型」と私は呼んでいる。組織階層の他に、フォルダ構成や勘定科目の体系もこれに含まれる。

自己参照型に「有効期間」を与えると、図2のようになる。上位組織IDは{組織ID+発効年月}の複合主キーを持つテーブル「期間別組織属性」の属性として置かれる。期間別組織属性の上に存在する同じ組織IDを持つ複数レコードが存在するとして、それを発効年月順に並べて得られる後続レコードの発効年月が、先行レコードの失効年月として導出される。図2では、組織Dはそれまで組織Cの下位組織であったが、2021/04から組織Bの下位組織に切り替わる例が示されている。

続いて「部品表型」だが、その典型例は文字通り部品表だ(図3)。自己参照型ではそれぞれの組織は階層全体の中で1度しか現れないが、部品表(品目構成)ではそれぞれの品目は1度以上現れ得る。図3の品目Cや品目Eはいわゆる共通部品の例で、構成上何度も現れる。なお、図3では品目構成がツリービューとして図示されているが、これは「正展開」の例である(*1)。
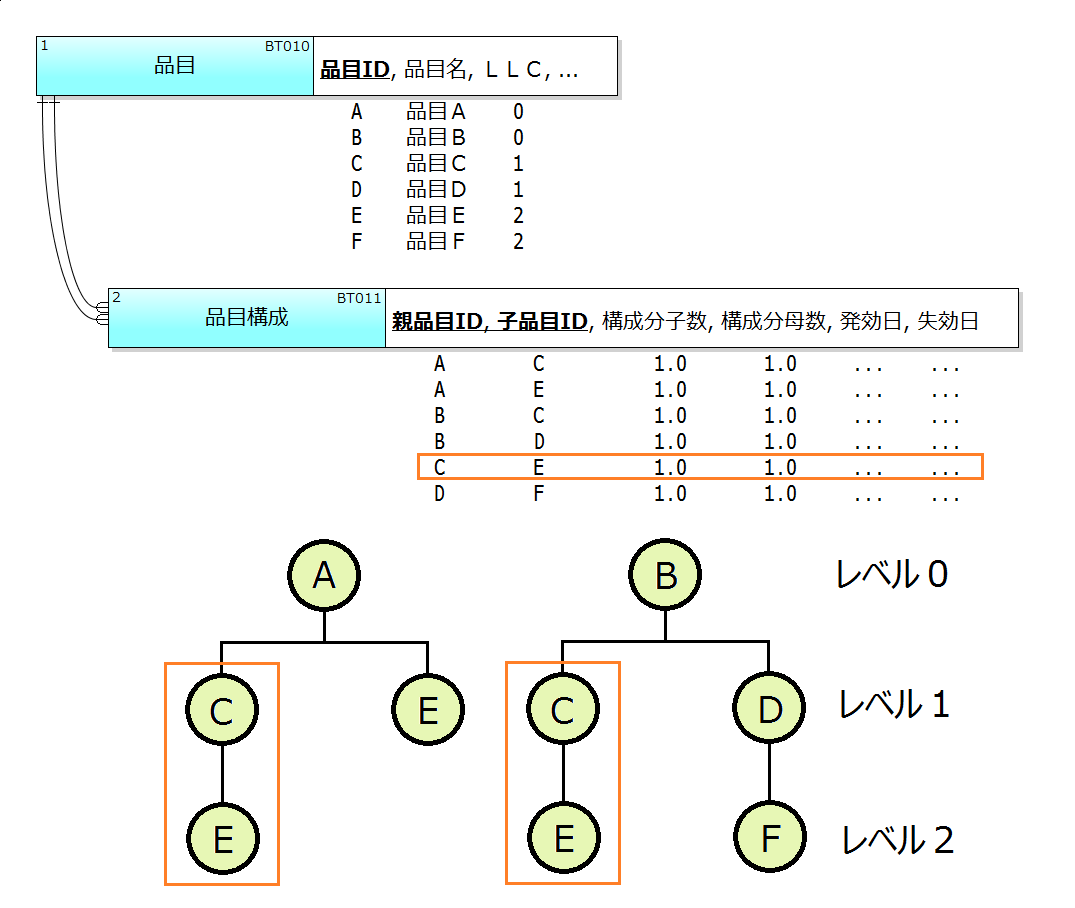
品目構成テーブル上の各レコードは、各品目の直下(シングルレベル)の構成品に関する情報を表現している。ゆえにこのタイプは「シングルレベル部品表」と呼ばれることがある。この他に「集約部品表」と呼ばれる古いタイプも存在する。どう違うのだろう。
たとえば図3では、品目Cが「品目Aと品目Bとの共通部品」として定義されている。しかし、その品目Cの構成品がEであることは、品目構成テーブル上では1レコード(オレンジ色の枠)だけで表されている。いっぽう、詳しくは述べないが集約部品表では品目Aと品目Bのそれぞれで定義されなければいけない。これは品目Cの構成定義が矛盾する可能性があるということで、ようするに集約部品表は「正規化されていない部品表」である。シングルレベル部品表における「構成品の構成比は{親品目ID+子品目ID}の複合主キーに関数従属する」という論理的な認識と実現は、まさにRDBの登場とともに得られたものだ。
図3に有効期間(発効日と失効日)がすでに置かれている点に注意してほしい。構成品は特定の時期から追加されたり廃されたりすることがあるので、有効期間は欠かせない。多くの場合、同じタイミングでの構成品Xの失効と構成品Yの発効、すなわち構成品XからYへの切替のために利用される。
■構成要素のレベル管理
さて、階層型のデータ構造において、構成要素の「レベル」が把握されていなければいけない。その必要性を理解するために、組織別の月次売上集計処理を考えてみよう。
それぞれの組織の固有な月次売上が1万円だったとする(下位階層を擁する組織に固有の売上があるのは多少不自然なのだが)。それぞれの組織の売上1万円の他に、階層に応じた「下階層組織の売上合計額」を計算することを考える。そのロジックはどのようになるだろう。

図4のように、直上位階層への積上げ操作を、最下層から上位層へ向かって順に実行するやり方が合理的である。当該階層から下位の集計がすでに終わっているゆえに、その合計額と各組織固有の売上額(1万円)の合計を安心して上位組織に積み上げていける。その過程で参照される情報が、各組織の階層上のレベルである。図1のモデルでは組織ID毎にレベルが決まるが、有効期間が付与されたモデル(図2)を前提にした図4では、{組織ID+集計年月}毎に決まる点に注意してほしい。
部品表型においても同様の考慮が必要になる。品目構成にもとづく原価集計等において、各品目について「品目構成全体における最下位のレベル(LLC, Low Level Code)」が手掛かりになる。たとえば図3上の品目Eは、レベル1と2で使われているが2のほうが深いのでLLCは2である。その値が深い品目から、直上位品目への原価積上操作を進めることになる。各組織のレベルと同様、各品目のLLCを設定するためのアルゴリズムを考えるのは、良く出来たパズルを解くように楽しい。
以上、階層型データ構造の代表である自己参照型と部品表型を説明した。実際の構造とデータの格納様式の対応関係をじっくり理解しよう。なお、これらのモデルが複合主キーを駆使したものであることを付言しておきたい。階層構造は、すべての主キーを{id}にするDB設計スタイルでは理解できない業務知識のひとつだ。複合主キーの必要性を雄弁に語る例としても参考にしてほしい。
*1.正展開では、品目テーブル上の品目IDに対して、親品目IDが一致するような品目構成が読み込まれる形で構成展開される。結果的に、下位構成品の方向に展開が起こる。逆展開はその反対で、子目IDが一致するような構成が探索されるため、上位使途品への展開が起こる。正展開は製造指示の作成において利用され、逆展開は使途分析や原価集計において利用される。