わかりやすさのためにタイトルを待機児童の話っぽくしたが、医療福祉、老人福祉、介護福祉、障碍者福祉、生活保護といった広い業務分野をカバーするものだ。福祉事業者の許認可、利用待機住民の把握、適合施設への誘導、利用料の納付や支払といったさまざまな業務を支援するデータモデルを考えたので紹介したい。
◆法人と行政格
まず図1は、福祉行政に関わる法人を中心にしたモデルだ。各法人は「法人行政格(2)」という”各種行政に関わる事業所の法人格”を取得する。福祉行政に限らず、たとえば食品衛生管理事業者や土地・不動産取引事業者を含めて行政格を定義してもいい。行政格には各自治体が個別に管理したい属性項目の一覧が年次で定義される(3,4)。各法人は行政格を取得する際に、それらの項目値を自治体に申請して許認可を受ける(10,11)。

法人そのものの属性の他に、法人が所有する施設についても既定の属性項目の一覧(5)に対する項目値を申請しなければいけない(6)。保育園であれば、「保育士数」や「過去3年間の退職者数」といった情報が欲しいところだ。多岐にわたるがそれらの多くがシステムの管理情報から自動設定できるもので、虚偽記載できる余地は少ない。あらためて入力すべき項目がそれほど多くないということでもある。
◆住民と福祉格
続いて図2は、施設の利用を希望する住民まわりのモデルだ。住民は必要に応じて(児童福祉の場合は年齢に応じて強制的に)「住民福祉格」を取得する(2)。それぞれの「住民福祉格」には、法人同様に年次で自治体固有の属性項目一覧が定義されており(4)、住民が福祉格を申請する際、既定の項目値(14)を入力することになる。
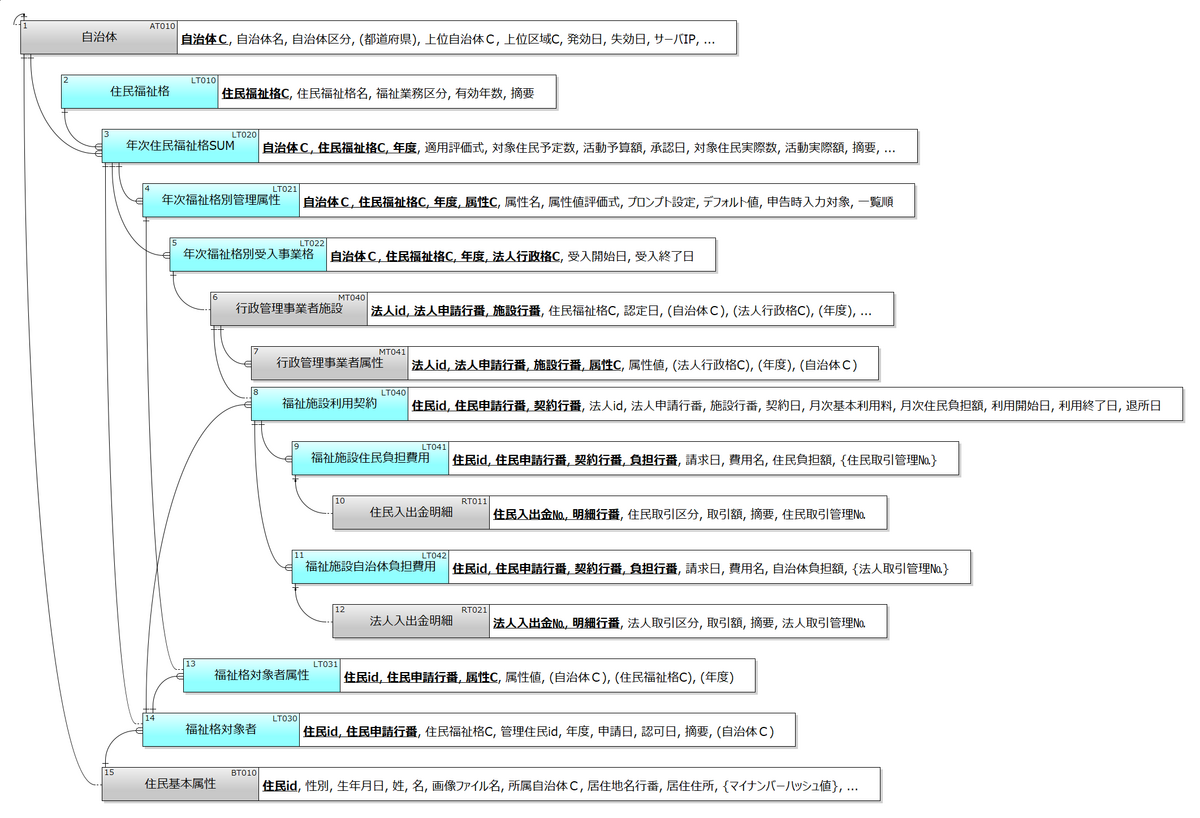
たとえば「保育園利用対象年齢児」の福祉格が与えられた住民の保護者は、たとえば「保育園利用希望事由」、「保育希望時間帯」、「希望保育園名」といった属性項目の値を登録する。他にも保護者の職業や所得や資産状況等が含まれるだろうが、これらは自治体システムで一元管理されているので自動設定できる。法人と同様、住民が虚偽記載できる余地は少ないし、あらためて入力する項目もそれほど多くはない。
施設決定に関して言い添えると、兄や姉が入園している施設を優先希望できることになっている(我が家もそうだった。保育士が子供を扱いやすくなるし、何よりも送り迎えが1回で済むからだ)。そうでなくても保護者としては希望施設を指定したい。ゆえに福祉格対象者属性にはその第一希望から第三希望までが載っていてほしい。さらに、上述した「過去3年間の退職者数」が多めの施設は経営姿勢に問題がありそうだから避けたいと保護者は考えるので、忌避希望施設を含めてもよい。そういった保護者のきめ細かい意向を、わざわざ役所に出向かずに自分用の自治体ポータルから入力できるようでなければいけない。
利用施設が決まったら「福祉施設利用契約(8)」が登録され、利用料の引き落としや業者への補助金の支払いがなされる。住民や自治体の負担額は住民の福祉格属性(13)によって自動的に決まる。
このようなしくみがあれば、待機児童の状況を捉えやすくなるだけでなく、悪質な事業者や住民をスクリーニングしやすくなる。情報管理が合理化されることで事務コストが劇的に減って、ケースワーキングや抜打検査の頻度を増やせるからだ。児童福祉まわりでの住民による不正が多いとは思えないが、生活保護申請あたりの不正は確実に減らせるだろう。
申請といえば、福祉行政の「申請主義」は「プッシュ型」に是正されるべきだ。住民に関する多くの情報が把握されているからには、福祉格を自動付与できる余地が広がる。自動付与したうえで、その福祉格別に定義されている各種施策(今回のモデルには含めていないが「住民支援施策」という名前で別途存在する)を自治体側から当該住民に提案できるようになる。煩雑な申請手続きを乗り越えない限り福祉サービスを受けられない「申請主義」のもとでは、本当に必要な住民にサービスが届かないだけでなく、プロの福祉行政ハッカーの暗躍を許すことにもなる。「プッシュ型」への転換は、自治体システムの合理化がもたらす効果の中でもとくに重要といっていい。
◆「自治体システム1700問題」を解決するために
こういった抜本的刷新には、多様なデータ項目を無駄なく矛盾なく保持するための広域データモデルの確立が欠かせない。もちろん簡単なことではない。上掲のモデルで示した「住民福祉格」や「法人行政格」といった誰も考えたことのない概念も必要で、そういう要素は現行業務をどれだけ分析しても見えてこない。ある種の発想の飛躍が求められる。難しいことだが、それこそが自治体システムの標準・統一化で求められる最優先課題である。
その意味で、しつこく言うのだが、全国で運用されている1700の自治体システムの存在を是認したまま「ガバメントクラウドへの移行」と「業務フローの標準化」でお茶を濁そうとする国の方針は間違っている。膨大な費用と手間暇がかかるわりにたいした効果が見込めないからだ。
そうではなく、今回説明したような「各自治体の独自性を可変的に組み込めるデータベース構造」の確立を優先し、これを核として全国の自治体システムを1700個から1個(か僅少)に統合することを目標とすべきだ。言うまでもなく、国全体での自治体システムの開発・保守・運用コストを大幅削減できるからだ。
そのうえで自治体毎に独特な業務フローやデータ処理機能が存在したとしても、地域性や歴史的経緯が反映された結果であるからには許していい。そのために、全国統一アプリ群を提供するいっぽうで、各自治体が独自のサブシステムを立ち上げて固有機能を持てるようにすればいい。その開発・保守は地場の業者にまかせていいが、その費用の総額(および明細)は公開されるべきだ。それが他の自治体に比べて高くても、住民が納得できるのであれば許される。納得できないのであれば、自治体は標準機能で対処できるように業務を改善しなければいけない。
ようするに、データモデルが全国で統一されることが肝要である。情報システムは何のために存在するのか。それは「既定の業務フローを実現するため」ではなく、文字通り「既定の情報(データベース上の項目値)を維持・管理するため」に存在する。ゆえに情報システムの仕様策定は「どんな情報を管理したいのですか?」の問いから始められなければいけない。「どんな業務をやりたいのですか?」や「どんな画面が欲しいのですか?」などは、”管理したい情報の論理構造”を明らかにした後で問われるべき些末な問題でしかないし、そこらへんに自治体毎の独自性が発揮されてもかまわない。