日本では1700以上ある自治体が、個々に情報システムを開発・運用している。自治体あたりで平均すると年間2億円の開発・維持費がかかっているが、これは2008年に自治体システムを統合した韓国での5倍以上だ。この壮大な無駄を「ソフトウエア産業の振興になる」と強弁する向きもあるが、納税者としてはとうてい納得できない。どう考えても日本に自治体システムは1基あればいい(日経XTECHの参考記事「2023年は正念場、自治体システム標準化に向けて現役の県職員が提言」)。
システムの統一における障害のひとつが、自治体毎の個別施策をどうするかという問題だ。ある種の業務分野では自治体の地域性が色濃く反映される。そういった施策はシステム仕様を複雑にするが、地方自治の原則だけでなく地元の諸事情に沿っているという優れた面もあるので無視できない。
個別施策をどのように統一システムに取り込めばよいのか。重要な検討課題でありながら、管見の限り決定的なアイデアが生まれているようには見えない。原因は2つ考えられる。まず、自治体システムの標準化が「業務フローの標準化」を基本方針として進められているためではないか。個別施策の本質は「独特な業務フロー」にはない。「扱っているデータ項目や業務ロジックが独特」であるゆえに「個別」なのであって、業務フローが独特なのはその結果の上っ面の問題でしかない。ゆえに、業務フローばかり見つめてもたいしたことはわからない。
もうひとつの原因は、図1の上のような発想で仕様化しているためではないかと私はにらんでいる。個別施策毎に専用のサブシステムを仕様化するのではなく、単一サブシステムの中で個別施策を自由に定義して扱える枠組みを創造する必要がある。
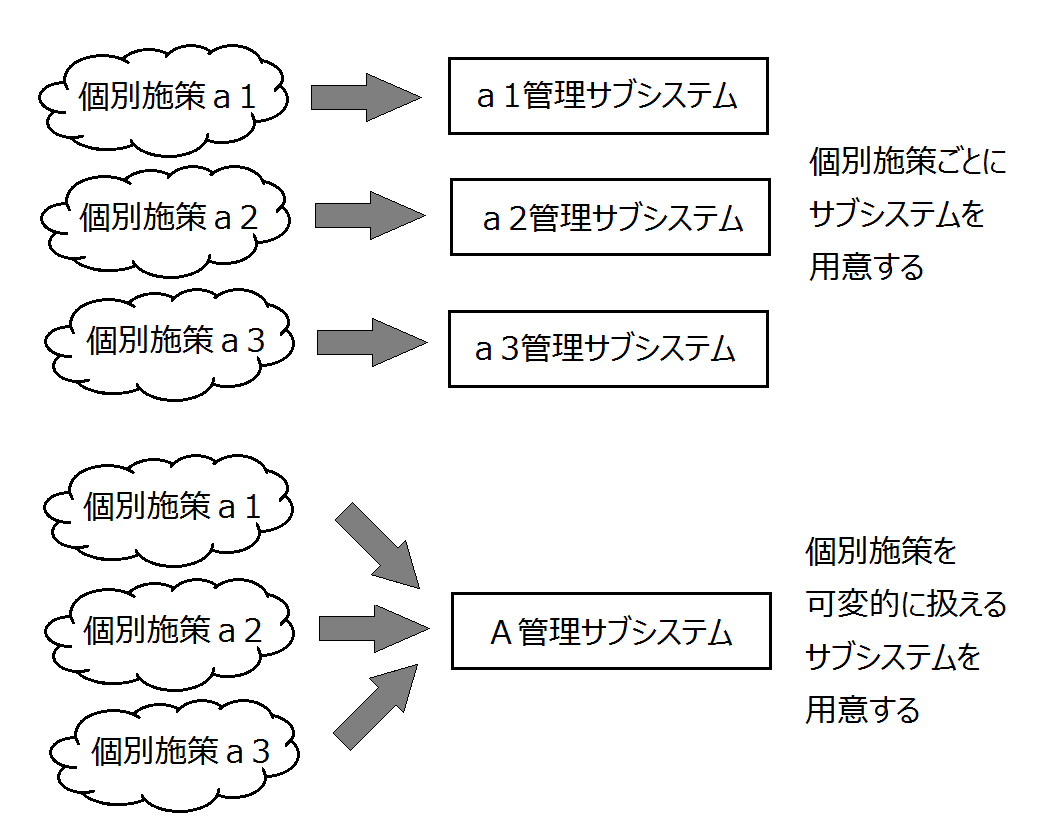
個別施策を自由に定義して扱える枠組みとはどのようなものか。類似の個別施策を抽象化したうえで、個別施策を可変的に扱えるデータモデルを用意することによってそれは実現できる。なお、a1,a2,a3は異なる自治体による個別施策である場合もあるし、同一自治体内で並立する場合もある。前者の例として「固定資産管理」、後者の例として「住民福祉管理」のデータモデルで説明しよう。まずは「固定資産管理」のモデルを見てほしい。
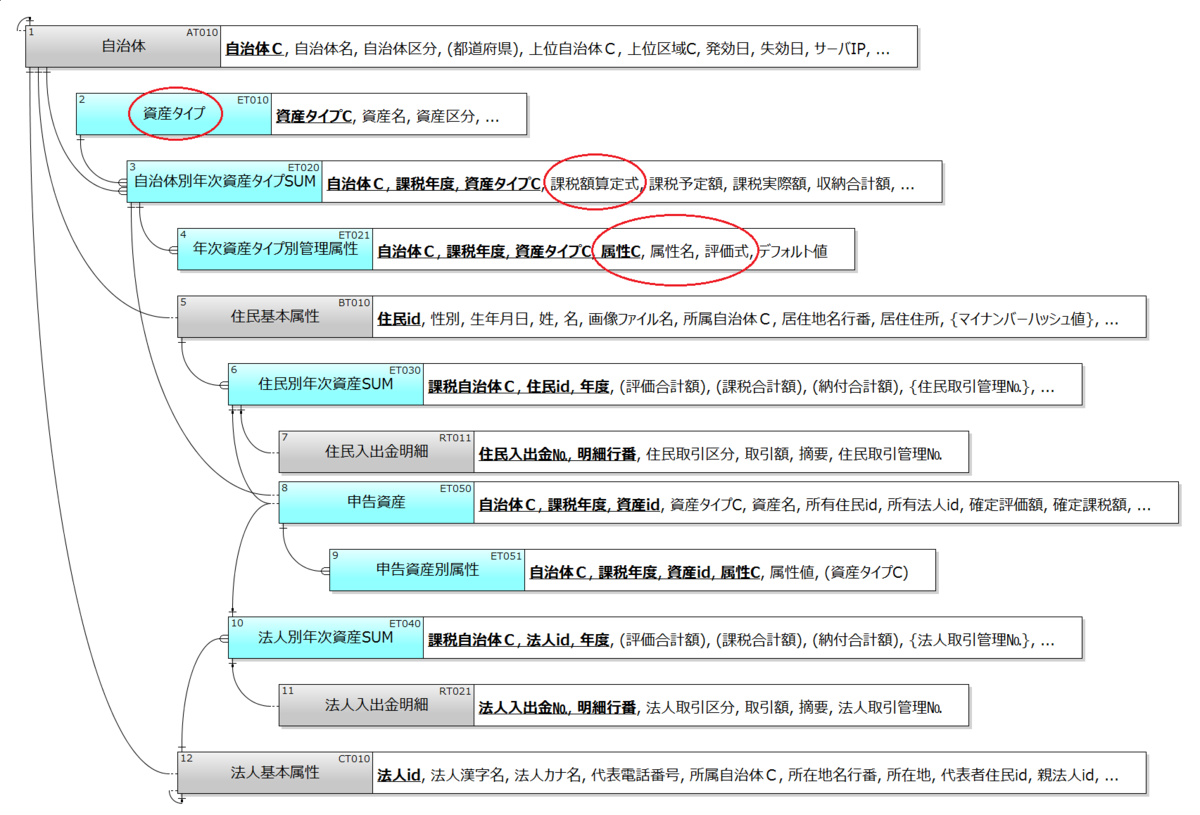
赤丸で囲った部分に注目してほしい。事前に資産タイプ(2,モデル上のテーブル番号)が定義されており、各自治体は年度毎に資産タイプ向けの計画を課税額算定式とともに設定する(3)。計算式には多彩な計算要素が含まれるが、それらは年次計画毎に資産の属性一覧としてあらかじめ設定されている(4)。住民および法人が申告した資産には規定の属性が設定され、評価額と課税額が決定される(8,9)。紛らわしいが4の「評価式」は、資産の評価額を計算するための式ではなく、各資産(8)に付与される属性(9)がとる値の妥当性評価のための式である。資産評価額の設定式は別途用意したほうがよさそうだが、部分的には手作業での入力が避けられないかもしれない。
どのような計算要素を用意してそれらにどのような課税額算定式を適用するかは、各自治体が自由に決めてよい。こうした「計算要素と業務ロジックの可変的定義」が、個別施策を標準システムに取り込むための基本戦略である。
この考え方は図3の「住民福祉管理」向けのデータモデルでも活用されている。図2の資産タイプに対応する概念が「福祉格(2)」で、医療福祉、児童福祉、生活保護、老人福祉等のために住民に付与される「福祉行政上のプロフィール」のようなものだ。たとえば「ひとり親」は児童福祉系の、「後期高齢者」は老人福祉系の福祉格として定義されることになる。
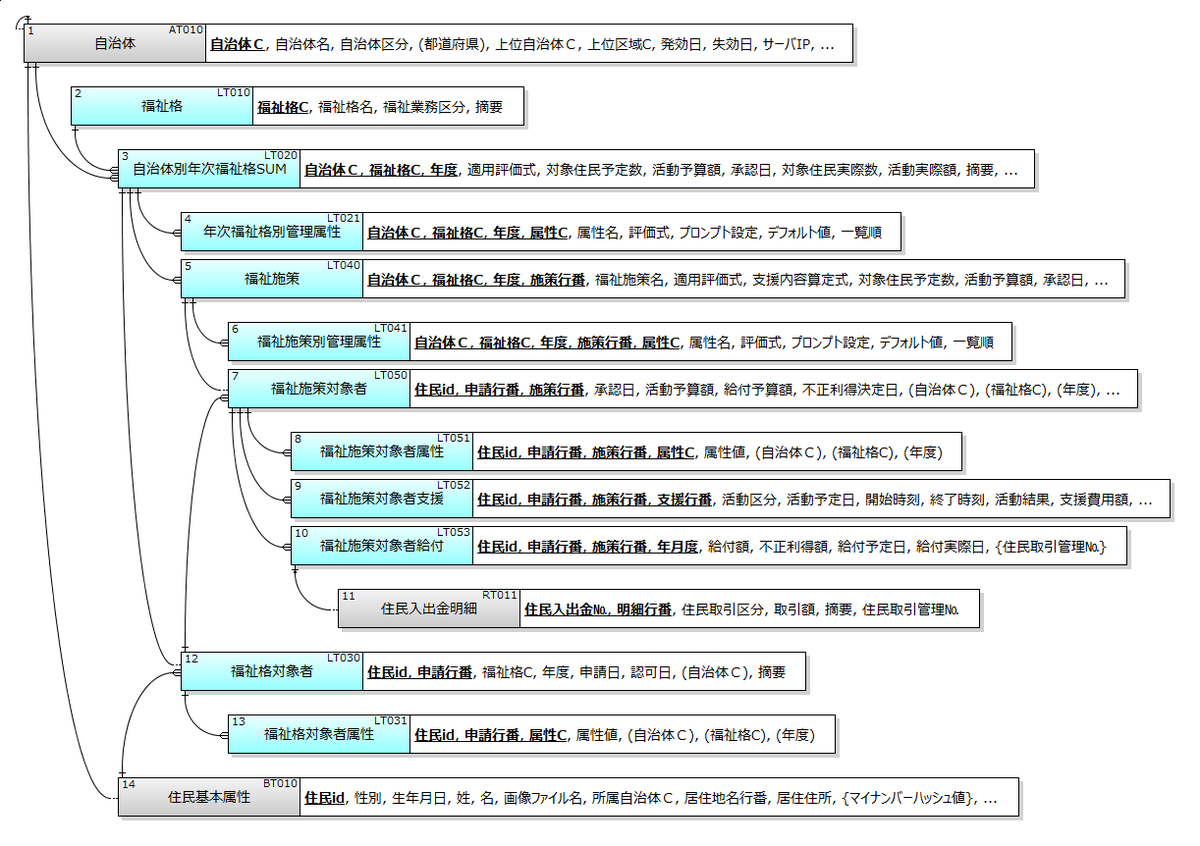
各自治体はそれぞれの福祉格毎に年次計画(3)を立案する。その際に、どのような属性を持つ住民に対してその福祉格が与えられるか(4)が独自に定義される。支援が必要な住民は前年度からの継続、または自己申告によって福祉格が認可・付与される(12,13)。さらに福祉格別の年次計画にしたがって、具体的な福祉施策(5)が複数件定義される。当該福祉格の対象者の全員または一部が福祉施策の対象(7)とみなされ、どのようなサービス支援(9)や給付(10)を受けるかが自動設定される。
従来の考え方では、医療福祉、児童福祉、生活保護、老人福祉のそれぞれ毎にサブシステムが用意されていた。福祉格の枠組みではそれらが単一のサブシステムに統合される。個別施策を取り込めるだけでなく、システム構成も簡素化されるということだ。自動計算される要素が増えるため業務も合理化され、結果的にケースワーカーを増やせるので、住民は良いサービスをより受給しやすくなるし不正受給が困難になる。
いかがだろう。以上の説明では「どのような情報が扱われるか」が語られているが「業務フローの標準化」は問題にされていない。なぜなら、データモデルを刷新することで業務フローは不可避的に変化するからだ。最初から業務フローの見直しを意図しているわけではない。また、このデータモデルが現行自治体システムのDB構造とは似ても似つかないという事実も知ってほしい。自治体活動においてどんな情報が扱われ、それがどんな論理構造を持っているか。それを抜本的に考え直すことで、ようやく業務フローの標準化や自治体DXの出発点に立てる。
重要なので繰り返そう。自治体システムの標準化において「業務フローの標準化」を一義的な目標にしてはいけない。とくに個別施策の問題は、業務の標準化では対処しようがないことは明らかだ。最初に目指すべきは「自治体システムが扱うデータの論理構造」の見極めである。ユースケースだの、業務フローだの、組織体制だの、UI/UXだの、業務ロジックだの、法令整備だのは、データモデルを確立した後でそれにもとづいてじっくり悩めばよい。